


Power BIやExcelでPower Query(パワークエリ)を利用しているときの必須スキル「重複行」の削除についてご紹介します!
主に以下のふたつのケースがあると思います。
- 重複する行のうち、上の行(古い行)を残したい。
- 重複する行のうち、下の行(最新行)を残したい。
これらの両方のケースについて紹介していきます!
今回は説明のため、以下のようなダミーデータを用意しました。
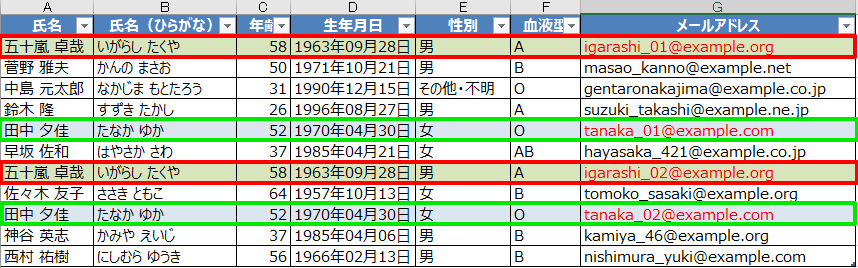
上のデータでは「五十嵐 卓哉」と「田中 夕佳」の2名が被っており、それぞれメールアドレスの@マークの手前が異なってます。
上の行(古い行)を残したいとき
まずは、上の行(古い行)を残す場合です。以下の画像のふたつを残します。
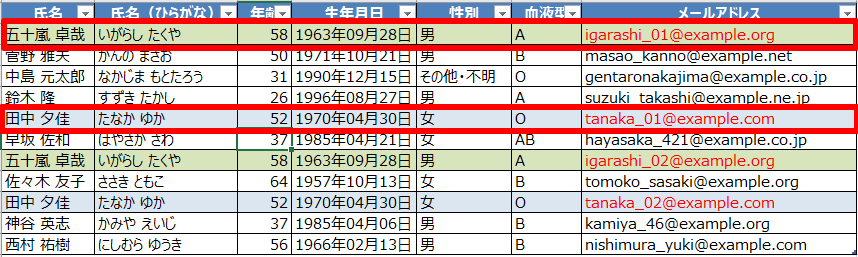
メールアドレスの@の手前が「_01」になっている方を残します。
まず、上記のリストをPower Queryで読み込みます。
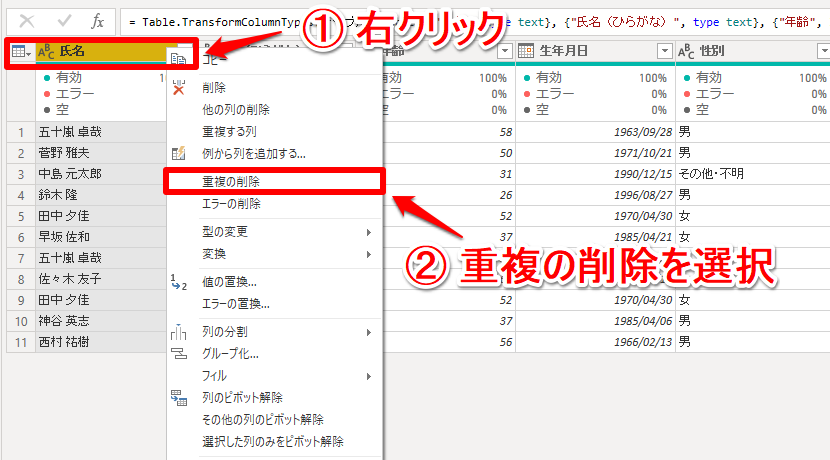
「氏名」の列名を右クリックし、「重複の削除」を選択します。
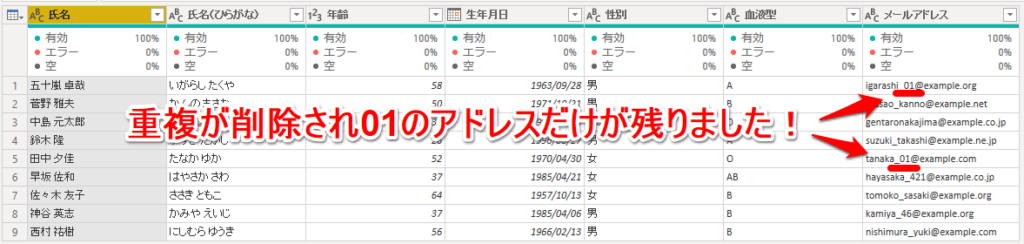
すると、上の行(古い行)だけが残りました!
下の行(最新の行)だけを残したいとき
次に、下の行(最新の行)だけを残します。
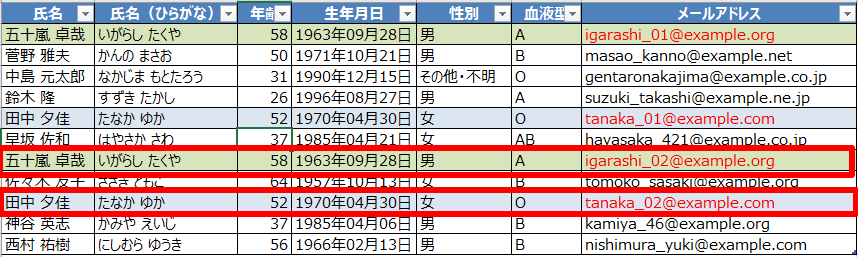
メールアドレスの@の手前が「_02」になっている方を残します。
リストをPower Queryで読み込んだら、「列の追加」から「インデックス列」を選択します。
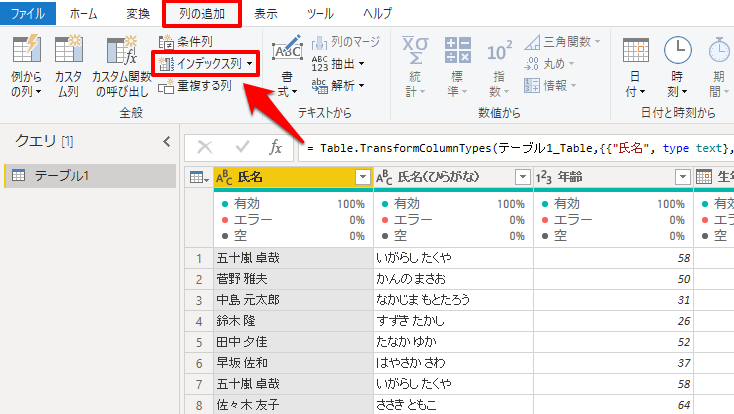
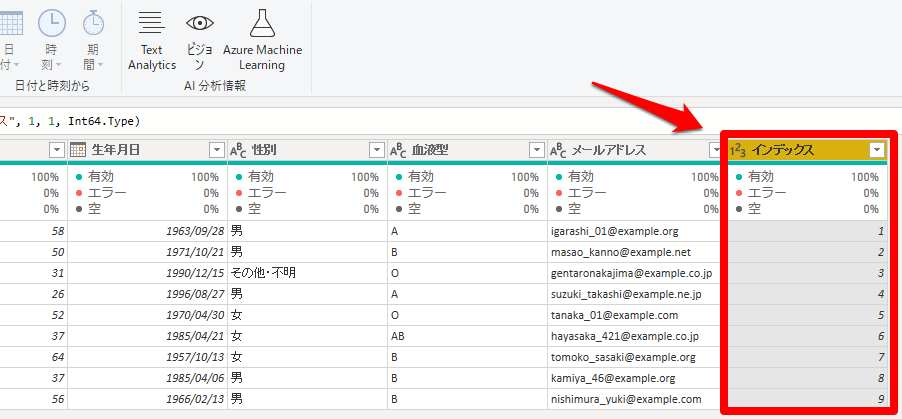
すると一番右の列に0もしくは1から始まるインデックス列が追加されます。
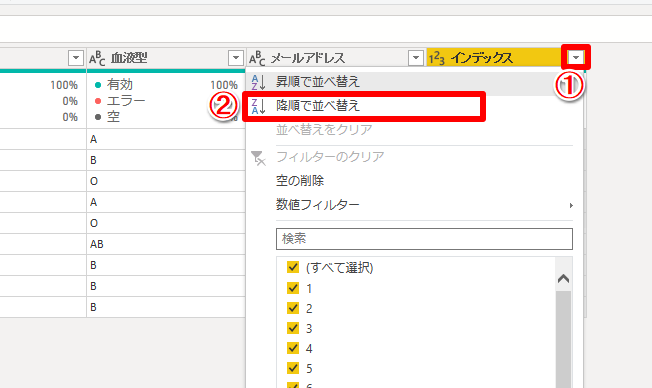
次に追加されたインデックス列の矢印マークから「降順で並べ替え」を選択します。
降順に並び変えた直後に、上の数式を見ると上記のようになっています。
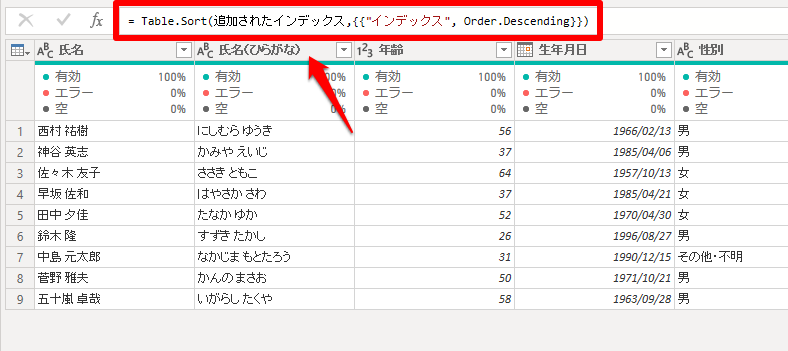
数式を以下のように変更します(赤字部分)
変更前:= Table.Sort(追加されたインデックス,{{“インデックス”, Order.Descending}})
変更後:= Table.Buffer(Table.Sort(追加されたインデックス,{{“インデックス”, Order.Descending}}))
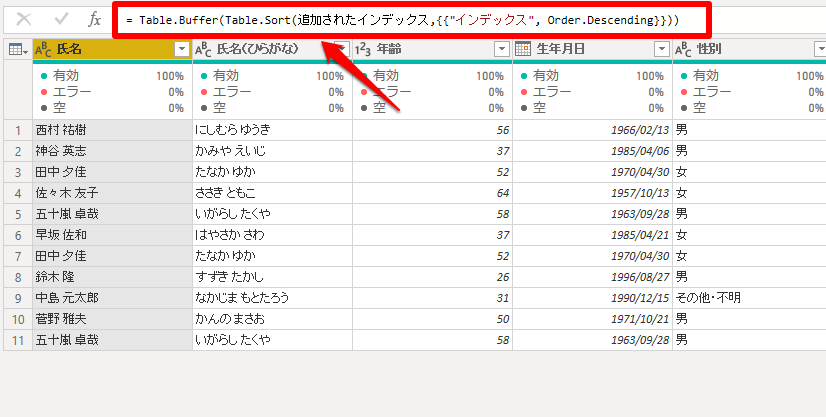
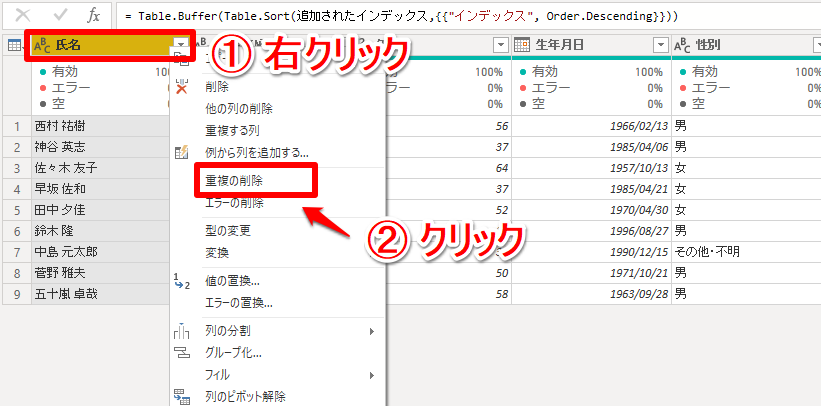
最後に「氏名」の列を右クリックして「重複の削除」をクリックします。
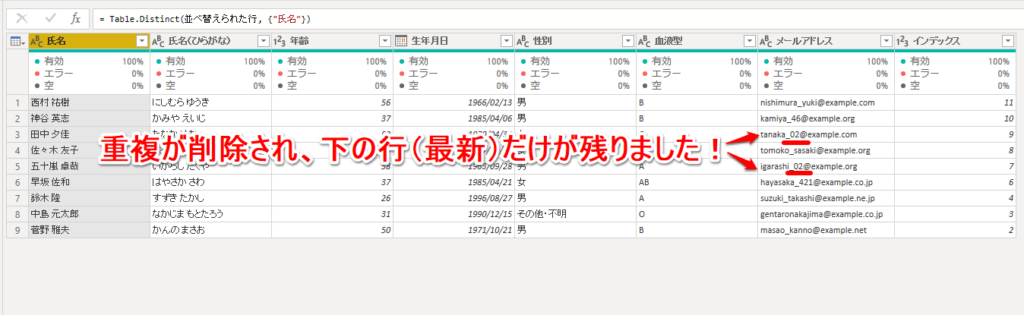
重複が削除され、下の行(最新の行)だけが残りました!
メールアドレスの@の前が「_02」の行だけが残っていることが確認できました。
以上で重複の削除は完了です!お疲れ様でした!

